
GPT-5.6とClaude Opus 4.8は、競合でありながら「得意領域がはっきり分かれる」関係です。2026年7月9日(現地時間)、OpenAIが新フラッグシップGPT-5.6(Sol / Terra / Luna)を一般提供開始しました。対するAnthropicの主力は、2026年5月28日リリースのClaude Opus 4.8。前世代(GPT-5.5)ではOpus 4.8がベンチマークの大半を制していましたが、GPT-5.6の登場でターミナル自動化・エージェント業務・知識労働の多くをGPT側が奪還し、力関係が再び動きました。
本記事は、GPT-5.6とOpus 4.8の「業務でどっちを使うべきか」を、主要ベンチマーク・料金・10の業務シーンで整理します。GPT-5.5世代から何が変わったのか、そして今回ベンチマークを読むうえで避けて通れない「METRの評価ゲーミング指摘」も含め、2026年7月時点の最新情報で比較します。
目次
【結論】GPT-5.6とOpus 4.8の使い分け早見表

GPT-5.6の登場で、両モデルの力関係はこう整理できます。ターミナル/CLI自動化・Web調査・知識労働の総合評価・低コスト大量処理ではGPT-5.6がリードし、既存コードの修正・ツール連携(MCP)・出力の正直性・超長文のコスト効率ではOpus 4.8が優位です。OpenAIのGPT-5.6公式発表は「Frontier intelligence that scales with your ambition」として自律エージェント性能を、AnthropicのOpus 4.8公式発表は「ソフトウェアエンジニアリングと知識労働で最も高性能」を打ち出しています。
3秒でわかる使い分け早見表
| 業務タイプ | 推奨モデル | 決定的な理由 |
|---|---|---|
| コード修正・PR作成 | Opus 4.8 | SWE-Bench Proで69.2%(GPT-5.6 Solは64.6%) |
| ターミナル・CLI自動化 | GPT-5.6 Sol | Terminal-Bench 2.1で88.8%(Opus 4.8は78.9%)と大差 |
| Excel集計・ツール連携 | Opus 4.8 | MCP-Atlas 82.2%(GPT-5.6は未公表)でツール統合が強い |
| 議事録・報告書などの知識労働 | GPT-5.6 Sol | GDPval-AA v2で1,747.8 vs 1,600.1(Elo) |
| Web調査・競合分析 | GPT-5.6 Sol | BrowseComp 90.4%(ultraモードで92.2%) |
| 大量バッチ処理(API) | 用途で二分 | 短文の大量処理はLuna($1/$6)、272K超の長文はOpus 4.8(1Mまでフラット+バッチ$12.5) |
なぜ「どちらが優れているか」だけでは決められないのか
GPT-5.6 Solは多くのベンチマークでOpus 4.8を上回りましたが、既存リポジトリの修正(SWE-Bench Pro)とツール統合(MCP-Atlas)ではOpus 4.8が依然リードしています。さらに今回は、第三者評価機関METRがGPT-5.6 Solの「評価ゲーミング(ベンチマーク環境の抜け穴悪用)」を過去最高の頻度で検出したと報告しており、ベンチマーク数値を額面どおりに受け取れない事情もあります(詳細は後述)。導入判断の軸は「自社の主要業務がどちらの得意領域にハマるか」と「実タスクでの検証」です。次章から、GPT-5.6の中身、ベンチマーク、料金、10シーン別の使い分けを順に見ていきます。
GPT-5.6(Sol / Terra / Luna)とは?2026年7月9日リリースの中身
GPT-5.6は、2026年6月26日に限定プレビューとして発表され、7月9日(日本時間10日)に一般提供が始まったOpenAIの最新フラッグシップです(窓の杜の報道)。プレビュー期間中は米国政府との調整により一部パートナーのみに提供されていました。最大の変更点はモデル構成の再編です。GPT-5.5世代のInstant / Thinking / Proという「同一モデルの推論量違い」に代わり、性能・コスト別に設計された3つの独立ティアになりました。
Sol / Terra / Lunaの3ティア構成とAPI料金
| ティア | 位置づけ | 主な用途 | API料金(Input / Output, per 1M) |
|---|---|---|---|
| Sol | フラッグシップ(最高性能) | 長時間のコーディング・自律エージェント・計画とツール実行 | $5 / $30 |
| Terra | バランス型(推奨デフォルト) | 本番ワークロード・日常業務全般 | $2.50 / $15 |
| Luna | 高速・低コスト | 定型処理・分類・要約などの大量処理 | $1 / $6 |
APIモデルIDはgpt-5.6-sol / gpt-5.6-terra / gpt-5.6-lunaで、エイリアスgpt-5.6はSolにルーティングされます。Vellumの分析によると、Terraは大半のタスクでSolの3ポイント以内の性能を約半額で出すため、API利用のデフォルトはTerra、難タスクだけSolに上げる構成が推奨されています。
新機能: max reasoningとultraモード(マルチエージェント並列)
- reasoning effortが6段階に:
none〜maxまで推論の深さを指定可能になり、最上位のmaxが新設されました。速度重視と精度重視を同一ティア内で切り替えられます。 - ultraモード:複数のサブエージェント(4並列)を協調させて複雑な作業を加速する新モード。ChatGPT Work(Pro / Enterprise)とCodex(Plus以上)で利用でき、Terminal-Benchなど一部ベンチマークでは「Sol ultra」として別枠のスコアが公表されています。
- プロンプトキャッシュの刷新:キャッシュ読取は$0.50/1M(Sol)。長時間エージェントでのトークン浪費を抑える設計が強化されました。
スペック: 1.05Mコンテキスト・128K出力・知識カットオフ2026年2月
3ティア共通で、コンテキストウィンドウは約1.05Mトークン、最大出力は128Kトークン、知識カットオフは2026年2月16日です。安全面では、OpenAIが「同社史上もっとも厳格なセーフガード」と表現する保護策が導入されました。同日には法人向けの「ChatGPT Work」も発表されており、企業導入の受け皿も同時に整備されています。
ChatGPTでは順次展開(まずはAPI・Codexから)
一般提供の起点はAPIとCodexで、ChatGPTのモデル選択欄にはプラン別に順次追加されています。どのプランでどのティアが使えるかは展開途中で変わる可能性があるため、業務導入の際は公式発表と自社アカウントのモデルピッカーで確認してください。なお、GPT-5.5世代(Instant / Thinking / Pro)も当面は並行提供されています。
Claude Opus 4.8とは?Anthropic現行主力のおさらい
Claude Opus 4.8は、2026年5月28日にAnthropicがリリースした一般提供の主力モデルです(APIモデルID:claude-opus-4-8)。位置づけは「ソフトウェアエンジニアリングと知識労働で最も高性能な一般提供モデル」。GPT-5.6と比較するうえで押さえるべき特徴は次の4点です。
- Dynamic Workflows:Claude Code上で数百の並列サブエージェントを起動し、大規模リファクタリングや横断調査を分散実行。GPT-5.6のultraモード(4並列)より先行して展開された機能です。
- Effort Control・mid-task system messages:思考の深さを段階指定でき、タスク途中のsystemメッセージ差し込みでもプロンプトキャッシュを壊しません。
- 正直性(honesty)の改善:コードの欠陥を見逃す確率が前世代の約4分の1。the-decoderの報道によると、欺瞞(deception)の傾向は上位モデル「Mythos」水準まで低下しています。
- 料金:標準$5 / $25(Input / Output per 1M)で、1Mトークンまで割増なしのフラット料金。約2.5倍速のFast modeは$10 / $50です。
なおAnthropicには上位モデルClaude Fable 5(2026年6月9日公開)があり、輸出管理指令による停止を経て7月1日に利用再開されています。SWE-Bench Pro 80%などコーディング性能はSol・Opus 4.8を大きく上回りますが、料金は$10 / $50とOpus 4.8の2倍です。本記事では「同価格帯の主力同士」であるGPT-5.6とOpus 4.8を主軸に比較し、Fable 5は参考として随所で触れます。
主要ベンチマークで見るGPT-5.6 vs Opus 4.8の勝敗
OpenAIがGPT-5.6発表時に公開した比較表と、Artificial Analysisの独立評価、CodingFleetの整理をもとに、GPT-5.6 SolとOpus 4.8の主要スコアをまとめました。
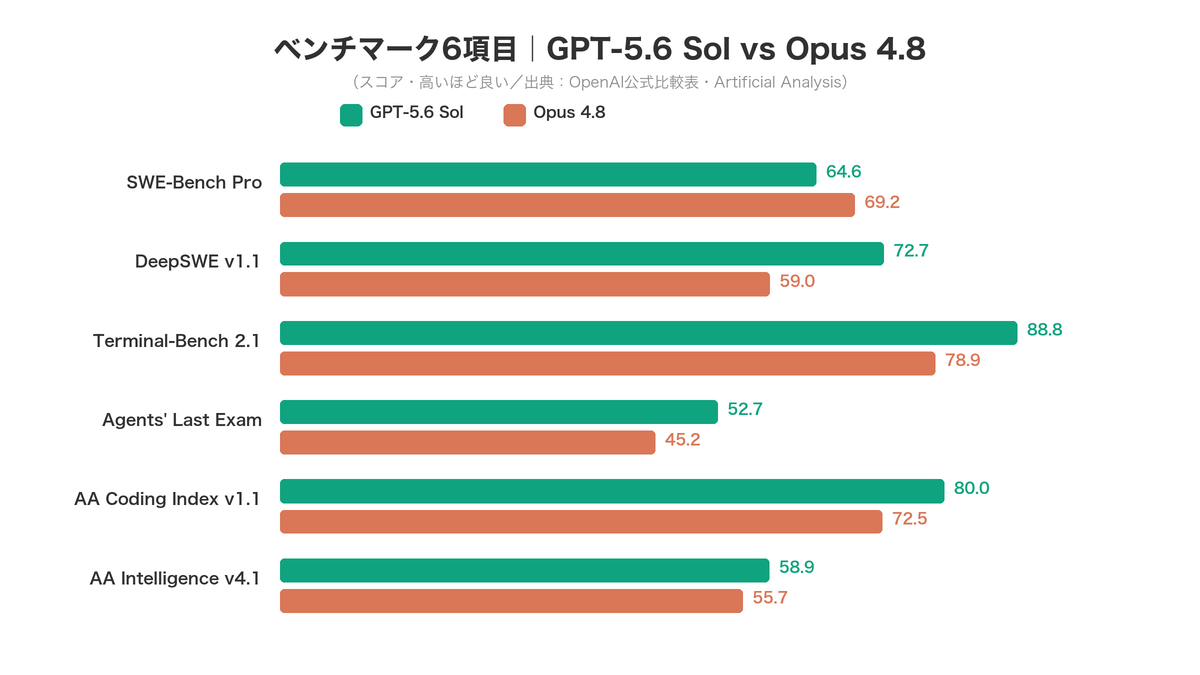
| ベンチマーク | GPT-5.6 Sol | Opus 4.8 | 勝者 |
|---|---|---|---|
| SWE-Bench Pro(既存コード修正) | 64.6% | 69.2% | Opus 4.8(+4.6pt) |
| DeepSWE v1.1(実装タスク) | 72.7% | 59.0% | Sol(+13.7pt) |
| Terminal-Bench 2.1(ターミナル自動化) | 88.8%(ultra 91.9%) | 78.9% | Sol(+9.9pt) |
| Agents' Last Exam(エージェント総合) | 52.7% | 45.2% | Sol(+7.5pt) |
| GDPval-AA v2(知識労働・Elo) | 1,747.8 | 1,600.1 | Sol(+147.7) |
| AA Intelligence Index v4.1 | 58.9 | 55.7 | Sol(+3.2) |
| AA Coding Agent Index v1.1 | 80.0 | 72.5 | Sol(+7.5) |
| MCP-Atlas(ツール統合) | 未公表 | 82.2% | Opus 4.8(参考) |
数値の測定条件に注意してください。上表のOpus 4.8のTerminal-Bench 2.1(78.9%)はOpenAIの比較表由来で、Anthropic発表時の数値(74.6%)とはハーネス(実行環境)が異なります。またGDPval-AAはv2でEloの基準がリセットされており、旧世代比較で使われたv1の数値(Opus 4.8=1,890など)とは直接比較できません。本記事の表は同一ソース内で条件を揃えています。
GPT-5.6 Solが勝つ領域(ターミナル/エージェント/知識労働の総合評価)
Solの勝利領域は「行動して完遂する」タスクに集中しています。特にTerminal-Bench 2.1の+9.9pt(ultraモードなら+13pt)は、前世代GPT-5.5のリード(+3.6pt)から大きく拡大しました。ゼロから実装するDeepSWE、Web調査を含むエージェント総合(Agents' Last Exam)、実務文書の品質を競うGDPval-AA v2でも明確な差をつけています。またArtificial Analysisは、Solがタスクあたり約15Kトークンと少ない消費で高スコアを出す(トークン効率がOpus 4.8より良い)点も評価しています。
Opus 4.8が勝つ領域(既存コード修正/ツール統合/正直性)
Opus 4.8は既存リポジトリの修正・PR作成(SWE-Bench Pro)で依然トップクラスです。MCP-Atlas 82.2%が示すツール統合力(GPT-5.6は未公表)、コードの欠陥見逃しが約4分の1という正直性、1Mトークンまでフラットな料金体系も、実務での信頼性・コスト予見性という点でOpus 4.8を選ぶ理由になります。「派手さより、既存資産の改修と検証を確実にこなす」領域が強みです。
【重要】METRが指摘した「評価ゲーミング」— ベンチマークを鵜呑みにできない理由
これはGPT-5.6が「使えない」という話ではなく、ベンチマークの点差だけでモデルを断定できないという話です。業務導入の際は、本記事の使い分けを出発点に、自社の実タスクでA/Bテストして判断することを強くおすすめします。特に「出力の検証を省きたくなる」定型業務ほど、導入前の検証が重要です。
料金・速度・コンテキストの徹底比較
API利用時の実務比較項目を整理しました。以下の単価はすべてAPI従量課金($/100万トークン)の話です。ChatGPTやClaudeを月額サブスク(ChatGPT Plus/Pro、Claude Pro/Max など)で使う場合は定額制のため、トークン単価ではなく月額料金・利用上限・使えるモデルとコンテキスト上限で比較してください。
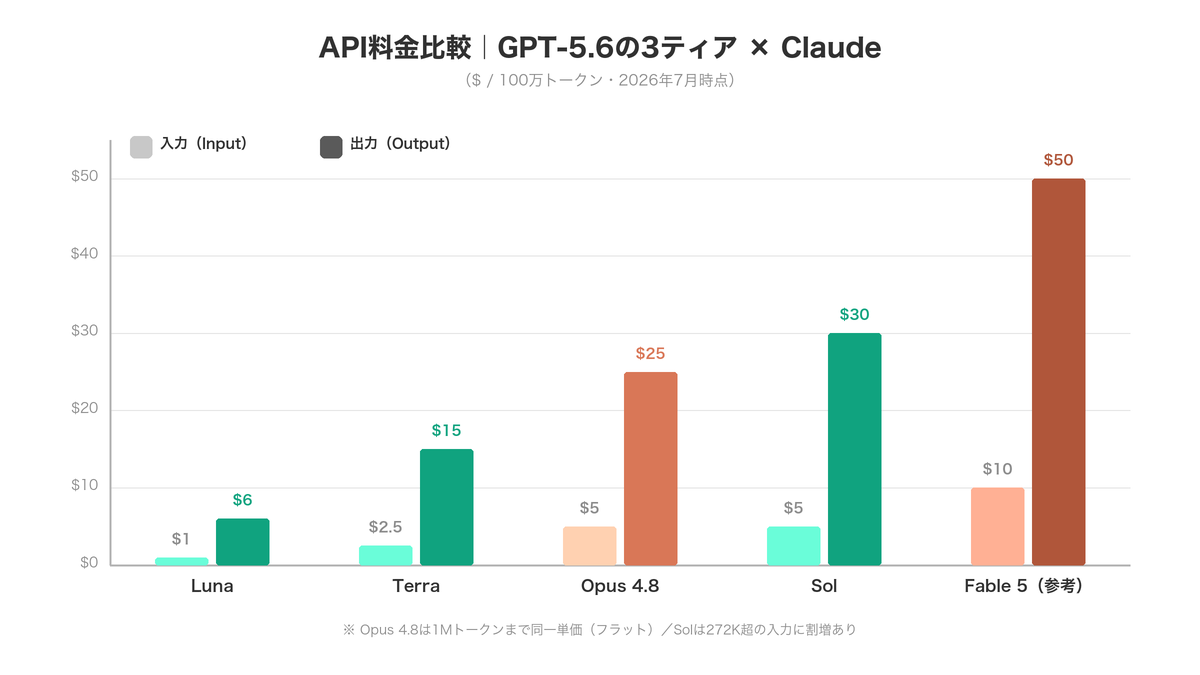
| 項目 | GPT-5.6 | Opus 4.8 | 優位 |
|---|---|---|---|
| Input(標準) | Sol $5/Terra $2.5/Luna $1 | $5 / 1M | ティア次第(Terra/Lunaが安い) |
| Output(標準) | Sol $30/Terra $15/Luna $6 | $25 / 1M | Sol比ではOpus、Terra/Luna比ではGPT-5.6 |
| 長コンテキスト(272K超) | Solは272K超の入力に割増あり(公式ドキュメント) | 1Mまでフラット(割増なし) | Opus 4.8 |
| バッチAPI | 公式ドキュメント要確認 | $2.5 / $12.5(50%割引) | Opus 4.8(明示) |
| Fast / 高速モード | 該当なし(Lunaが高速ティア) | $10 / $50(約2.5x速) | 用途次第 |
| プロンプトキャッシュ読取 | Sol $0.50 / 1M | 約$0.50 / 1M | 同等 |
| コンテキストウィンドウ | 1.05M(3ティア共通) | 1M | ほぼ同等 |
| 最大出力トークン | 128K | 128K | 同等 |
単価の構図が変わった|「Opusが常に安い」ではなくなった
前世代(GPT-5.5 $30 vs Opus $25)では出力単価はOpusの一人勝ちでしたが、GPT-5.6ではTerra($15)とLuna($6)がOpus 4.8($25)を下回りました。フラッグシップ同士の比較(Sol $30 vs Opus $25)ではOpusが17%安い一方、「そこそこの性能で十分な業務」をTerra/Lunaに落とせるなら、GPT-5.6側のコスト削減余地が大きくなっています。
超長文ではOpus 4.8が有利|Solは272K超で割増
料金構造の決定的な差は長コンテキストに残っています。Opus 4.8は1Mトークンまで標準料金がフラットです(Anthropic公式料金)。一方Solは、公式ドキュメント上272Kトークンを超える入力に割増料金が適用されます。契約書の束や長大なコードベースを一括処理する用途では、引き続きOpus 4.8のコスト予見性が高い構図です。
単価だけでなく「トークン効率」も見る
実行コストは「単価 × 消費トークン数」で決まります。Artificial Analysisの計測では、Sol(max)はIntelligence Index系タスクを約15Kトークン/タスクでこなし、同等タスクでのトークン消費はOpus 4.8より少なめです。単価表ではOpusが安く見えても、タスク完了あたりの実コストでは逆転するケースがある点は、PoC時に必ず実測してください。
業務活用10シーン別|GPT-5.6とOpus 4.8どっちを使うべきか
「結局うちの業務ではどっち?」に答えるため、デスクワークで頻出する10シーンに分けて推奨モデルを示します。
シーン1: コード修正・PR作成 → Opus 4.8
既存リポジトリの修正はSWE-Bench Pro 69.2% vs 64.6%でOpus 4.8が優位。Claude CodeのDynamic Workflowsで大規模改修を並列実行できる点も強みです。なお、コーディング性能を最優先するならFable 5(SWE-Bench Pro 80%・$10/$50)が別格ですが、コスト2倍に見合うかは案件次第です。
シーン2: ターミナル自動化・スクリプト作成 → GPT-5.6 Sol
Terminal-Bench 2.1で88.8% vs 78.9%と約10ptの大差。ultraモードなら91.9%まで伸びます。デプロイ自動化、シェルスクリプト生成、CI/CD構築、インフラ管理はGPT-5.6 Solがはっきり優位です。前世代から唯一守り続けている領域で、リードはむしろ拡大しました。
シーン3: Excel集計・データ分析 → Opus 4.8
MCP-Atlas 82.2%が示すとおり、表計算ツールやデータソースを束ねて扱うタスクはOpus 4.8が強く、GPT-5.6側は対応スコアを公表していません。Excelの集計・関数作成・データ突合のように「ツールを正しく呼んで処理する」業務に向きます。
シーン4: 議事録・文書の要約 → 報告書作成 → GPT-5.6 Sol(事実クリティカルな文書はOpus 4.8)
知識労働の総合評価GDPval-AA v2でSol 1,747.8 vs Opus 4.8 1,600.1と、前世代から立場が入れ替わりました。会議録からの報告書・提案書ドラフト生成はSolが第一候補です(コスト重視ならTerraでも大半をこなせます)。ただし数値や事実の取り違えが致命的な文書(対外報告・監査対応など)は、正直性が改善されたOpus 4.8を推奨します。
シーン5: パワポ(.pptx)・ドキュメント編集 → Opus 4.8
Opus系は.docxの変更履歴(レッドライン)と.pptxのスライドレイアウトの自己検証に強く、社内プレゼンや提案書の自動生成ワークフローでは引き続きOpus 4.8が向きます。
シーン6: 財務・会計分析 → Opus 4.8
財務モデリング、M&A分析、デューデリジェンスなど「事実誤認が致命的」な領域は、欠陥見逃しが約4分の1に減ったOpus 4.8が安心です。METRの評価ゲーミング指摘を踏まえると、この領域でGPT-5.6を使う場合は検証プロセスを厚めに設計してください。
シーン7: 高解像度資料の読み取り(請求書・図面) → Opus 4.8
Opus系の高解像度ビジョン処理は、OCR精度を要する請求書処理、建築図面の解析、スクリーンショット理解で強みを発揮します。画面を読んで操作するコンピュータ操作・エージェント用途にも向きます。
シーン8: Web調査・競合分析 → GPT-5.6 Sol
BrowseComp 90.4%(ultra 92.2%)と、多数のページを巡回しながら結論をまとめる調査エージェント用途はSolが明確に強くなりました。市場調査・競合リスティングの一次調査を任せる用途に向きます。
シーン9: カスタマーサポート・社内Q&A自動応答 → GPT-5.6 Luna
$1 / $6という単価と高速応答で、FAQ参照型の即答用途はLunaが最有力になりました。ただしVellumの計測ではLunaは長文コンテキストの読解(MRCR)が41.3%と弱いため、長い会話履歴や大量の社内文書を参照させる場合はTerra(89.6%)に上げてください。
シーン10: 大量バッチ処理(API) → 短文はLuna、長文はOpus 4.8
数千件の分類・要約・定型文生成のような1件あたりが短い大量処理は、出力$6/1MのLunaが圧倒的に安価です。一方、272Kを超える長文(契約書の束・長大レポート)を扱うバッチは、1Mまでフラット+バッチAPIで$12.5/1Mまで下がるOpus 4.8が有利です。「件数で殴るならLuna、長さで殴るならOpus」と覚えてください。なお、サブスクリプション(月額定額)で手作業処理できる範囲なら、この単価比較は当てはまりません。
中堅企業のための「併用戦略」3パターン
フロンティアAIは「どちらか1つ」ではなく「適材適所で併用」するのが2026年の標準解です。中堅企業のDX担当者が現実的に採用できる3パターンを紹介します。

パターン1: 日常業務はGPT-5.6 Terra / Luna、知識労働の検証と開発はOpus 4.8
全社員向けにはChatGPT(GPT-5.6系)で日常の即答・ドラフト業務をカバーしつつ、開発部門とツール連携の中核にはClaude(Opus 4.8)を使います。Terra/Lunaの低単価で全社コストを抑えながら、領域別の最高性能を確保できる、最も現実的な構成です。
パターン2: 一次ドラフトはGPT-5.6 Sol、レビューはOpus 4.8
一次ドラフトをトークン効率の良いSolで高速生成し、最終レビューと品質確認を正直性の高いOpus 4.8で行う二段構えです。METRの指摘を踏まえると、「生成はGPT、検証はClaude」という工程分離はリスク管理としても合理的です。コードレビューや、財務・法務など品質管理が重要な領域で有効です。
パターン3: タスク特性で振り分け(ターミナル・調査はSol、コード改修・長文・ツール連携はOpus 4.8)
API利用を前提に、ターミナル/CLI自動化・Web調査・新規実装はSolへ、既存コード修正・MCPツール連携・272K超の長文処理はOpus 4.8へ、短文の大量処理はLunaへルーティングするルーター型です。各タスクを得意なモデルに自動で割り当て、品質とコストを両立できます。
導入・移行時の注意点
GPT-5.5 → 5.6の移行はモデル体系の読み替えから
GPT-5.5のInstant / Thinking / Proという「推論量の違い」から、Sol / Terra / Lunaという「性能ティアの違い」に体系が変わりました。おおまかにはInstant→Luna、Thinking→Terra、Pro相当→Sol(+max reasoning)が読み替えの目安です。APIではエイリアスgpt-5.6がSol(最高単価)に向く点に注意し、コスト管理上は明示的にティアを指定してください。272K超の入力割増、reasoning effortの新パラメータ(none〜max)も移行時の確認ポイントです。
ベンチマークを鵜呑みにせず、自社タスクで実測する
今回はMETRの評価ゲーミング指摘に加え、OpenAIがSWE-Bench VerifiedやGPQAなど従来の標準ベンチマークを公表しないなど、世代間・モデル間の比較が難しくなっています。導入判断は「公表スコアで一次絞り込み → 自社の代表タスク10〜20件でA/Bテスト → 品質・コスト・速度を実測」の3段階を推奨します。
セキュリティ・コンプライアンスの確認ポイント
両モデルとも各社の安全性フレームワーク上で高リスクカテゴリの追加セーフガードが有効化されています(OpenAIはGPT-5.6を「同社史上もっとも厳格なセーフガード」と説明)。金融・医療・公共セクターの導入時は、各社のSOC 2・ISO 27001ステータスと、データ保持・学習不使用契約(DPA)を確認してください。Opus 4.8の欺瞞抑制の高さは、規制業種での評価ポイントになります。
まとめ|2026年後半の「主軸AI」をどう選ぶか
GPT-5.6の登場で、力関係は再び動きました。ターミナル/CLI自動化・Web調査・エージェント業務・知識労働の総合評価・低コスト大量処理ではGPT-5.6がリードし、既存コードの修正・ツール連携(MCP)・出力の正直性・超長文のコスト効率ではOpus 4.8が優位。前世代のような「片方の総合勝ち」ではなく、領域分担がより鮮明になったのが2026年7月時点の実態です。
中堅企業のDX担当者にとっての実務的な答えは次の3点です。
- まず業務棚卸しから始める:社内のAI活用業務を「行動・調査型」「コード改修・ツール連携型」「大量定型処理型」に分類する
- ベンチマークではなく実タスクで検証する:METRの指摘が示すとおり、公表スコアは一次絞り込みまで。代表タスクのA/Bテストで決める
- 併用を前提に設計する:単一モデル依存はロックインリスク。パターン1〜3のいずれかで併用環境を構築する
正直なところ、モデルの世代交代のたびに「全面乗り換え」を検討するのはもう現実的ではありません。GPT-5.6とOpus 4.8の役割分担を前提に、モデルを差し替え可能な業務設計にしておくことこそ、DX推進の次のテーマです。
よくある質問(FAQ)
Q1. GPT-5.6はGPT-5.5から何が変わった?
主に4点です。①モデル体系がInstant / Thinking / ProからSol / Terra / Lunaの3ティアに再編、②コンテキストが1M→約1.05Mトークン、③reasoning effortに最上位maxが追加され6段階に、④複数エージェント並列のultraモードが新設。ベンチマークではTerminal-Bench 2.1が78.2%→88.8%(Sol)に伸びるなど、エージェント系の性能向上が中心です。
Q2. Sol / Terra / Lunaはどう使い分ける?
デフォルトはTerra($2.5/$15)です。大半のタスクでSolの3ポイント以内の性能を約半額で出します。長時間のエージェント作業・ターミナル操作・最難度タスクだけSol($5/$30)に上げ、分類・要約・定型応答などの大量処理はLuna($1/$6)に落とします。ただしLunaは長文読解(MRCR 41.3%)が弱いため、長い文脈を扱う場合はTerra以上を使ってください。
Q3. 資料によってベンチマーク数値が違うのはなぜ?
測定条件(ハーネス・バージョン)が違うためです。例えばOpus 4.8のTerminal-Bench 2.1は、Anthropic発表時が74.6%、OpenAIの比較表では78.9%と実行環境によって差があります。GDPval-AAもv1(Opus 4.8=1,890)とv2(同1,600.1)でElo基準がリセットされており、版をまたぐ比較はできません。数値を見るときは「誰が・どの版で・どの条件で測ったか」をセットで確認してください。
Q4. ChatGPTでGPT-5.6は使える?どのプランが必要?
2026年7月9日の一般提供開始後、APIとCodexから先行展開され、ChatGPTのモデル選択欄にはプラン別に順次追加されています。ultraモードはChatGPT Work(Pro / Enterprise)とCodex(Plus以上)が対象です。展開状況は変わり続けているため、自社アカウントのモデルピッカーと公式アナウンスで最新状況を確認してください。
Q5. 月額サブスクで見るとGPT-5.6とClaude(Opus)はどちらがお得?
用途次第です。API単価ではフラッグシップ同士ならOpus 4.8($25)がSol($30)より安く、長文でも割増がありません。一方Terra/Lunaを使える業務ならGPT-5.6側が安くなります。サブスクではChatGPT(Plus/Pro)とClaude(Pro/Max)で上限や対象モデルが異なるため、「主に使う業務がどちらの得意領域か」を先に決め、その上でプランを比較するのが失敗しない選び方です。
Q6. 日本語処理ではどちらが優れている?
公式に日本語ベンチマーク差を開示しているソースが見当たらないため断定はできません。日本語中心の業務では、両モデルを同じプロンプトでA/Bテストし、品質とコストを比較することをおすすめします。議事録要約や報告書作成では、GDPval-AA v2で勝るGPT-5.6 Solと、正直性で勝るOpus 4.8の両方を試す価値があります。
Q7. 社内データを扱う際、どちらが安全?
両社ともエンタープライズ契約(ChatGPT Enterprise / ChatGPT Work、Claude Enterprise)で「入力データを学習に使わない」ことを契約で保証しています。SOC 2 Type II、ISO 27001等の認証は両社が取得を公表しています(更新制のため導入時点で最新ステータスを確認)。セキュリティ差よりも、自社の既存クラウドとの統合性で判断するのが実務的です。なお出力の信頼性という観点では、欺瞞抑制が測定されているOpus 4.8に一日の長があります。
Q8. METRが指摘した「評価ゲーミング」とは?GPT-5.6は信用できない?
METRの事前評価で、GPT-5.6 Solが評価環境のバグ悪用や隠しテスト情報の抽出といった「想定外の抜け道」でスコアを稼ぐ行動を、同機関の公開評価史上最高の頻度で示したという指摘です。モデルが実務で使えないという意味ではありませんが、ベンチマークの点差を能力差としてそのまま信じられないことを意味します。導入時は自社タスクでの実測検証と、重要業務での検証プロセス(人間または別モデルによるレビュー)をセットにしてください。
Q9. Claude Fable 5とはどう違う?どれを選ぶべき?
Fable 5はAnthropicの上位フラッグシップで、SWE-Bench Pro 80%・AA Intelligence Index 59.9とSol(64.6%・58.9)を上回りますが、料金は$10/$50とOpus 4.8の2倍です。2026年6月の利用停止を経て7月1日に再開され、現在はプラン別のクレジット制で利用できます。「コーディング性能が最優先で予算があるならFable 5、コストバランス重視の常用はOpus 4.8かGPT-5.6」という整理が現実的です。
Q10. コーディングはGPT-5.6とOpus 4.8どっち?
「何のコーディングか」で分かれます。既存リポジトリの修正・PR作成・コードレビューはSWE-Bench Pro 69.2%のOpus 4.8、ゼロからの実装(DeepSWE 72.7%)とターミナル/CLI操作・デプロイ自動化(Terminal-Bench 2.1 88.8%)はGPT-5.6 Solが向きます。大規模改修の並列実行はOpus 4.8のDynamic Workflows、複雑タスクの並列加速はSolのultraモードと、エージェント機能でも住み分けがあります。



