
目次
【2026年7月20日 更新】Claude Fable 5はMaxプランで恒久利用に、Proは使用クレジット制へ
Claude Fable 5の提供状況は、7月1日の利用再開後も何度も変わり続けました。当初「7月7日まで週次利用上限の最大50%まで追加費用なし」とされていた期間は、7月12日、さらに7月19日へと2度延長され、そして2026年7月18日、Anthropicはついに最終方針を発表します。7月20日からClaude Fable 5はMax・Team Premiumプランの標準機能として恒久的に含まれる一方、Pro・Team Standardプランは使用クレジットによる従量課金制に移行しました。プラン間で明暗が分かれる決着となったこの経緯を整理します(出典: Anthropic公式ヘルプセンター・GIGAZINE・THE DECODER、2026年7月18〜19日)。
| 項目 | 現在の状況(2026年7月20日時点) |
|---|---|
| Max・Team Premiumプラン | Fable 5が標準機能として恒久的に利用可能(週次利用上限の最大50%まで追加費用なし、期限なし) |
| Pro・Team Standardプラン | プランの利用上限には含まれず、使用クレジット(入力$10/出力$50)による従量課金。一回限りの無料クレジット(報道では$100相当)の対象 |
| Enterprise | プレミアムシートはサブスクリプション内で継続、標準シートはクレジット有効化が必要 |
| API | 変更なし(引き続き入力$10/出力$50の従量課金) |
| Free | 対象外 |
2度の延長から恒久化決定までのタイムライン
- 7月1日:米商務省の指令解除を受け、Fable 5が全世界で利用再開。7月7日まで週次利用上限の最大50%まで追加費用なしという条件が設定される。
- 7月7日:期限切れの数時間前、AnthropicがX(@claudeai)と公式サポート記事の更新のみで7月12日への延長を発表。専用のプレスリリースはなし。
- 7月13日:さらに7月19日までの再延長を発表。延長の理由は「加入者の反発」と明言されず、「プロモーション期間の延長」とのみ説明された。
- 7月18日:Anthropicが最終方針を発表。7月20日からMax・Team Premiumは恒久的にFable 5を含む一方、Pro・Team Standardは使用クレジット制へ完全移行すると告知。
- 7月20日:新方針が発効。Max・Team Premiumでの提供に期限は設けられていない。
なぜMaxだけ恒久化されたのか
Anthropicは方針転換の理由について、Fable 5の需要予測が難しく利用者側にもフラストレーションを与える形になっていたこと、データセンター容量の拡張が進み大規模な提供が可能になったことを挙げています(出典: Enterprise DNA、2026年7月)。一方で海外メディアは、低価格を打ち出す競合モデルの登場や、中国系ラボの値下げ圧力も方針転換の背景にあると報じています。Anthropicは当初、Fable 5をサブスクリプションから完全に外す計画だったものの、競争環境の変化を受けて撤回したとの見方です(出典: THE DECODER、2026年7月)。最上位プランの契約者を優遇し、Fable 5をMaxプランの差別化要因として位置づける狙いもあるとみられます。
Pro・Team Standardプランでの料金と使い方
Pro・Team Standardプランのユーザーは、使用クレジット(入力$10/出力$50、100万トークンあたり)を購入すればFable 5を引き続き利用できます。移行にあたって一回限りの無料クレジット(報道では$100相当)が付与されるため、まずはこの範囲で評価するのが現実的です。海外メディアは、システム設計・複数サービスにまたがる計画立案・難しいデバッグなど「高レベルの判断」が必要な場面にFable 5を絞り込み、日常的なコード生成やテスト作成、リファクタリングはコストが約5分の1のClaude Sonnet 5に振り分ける使い分けを推奨しています(出典: Digital Applied、2026年7月)。なお「週次上限の50%」はトークン数や金額に換算されていないため、実際の消費量はダッシュボードで確認するのが確実です。
復活後の安全対策とMythos 5の現状
7月1日の再開にあたって導入された、報告済みジェイルブレイク手法を99%以上ブロックする改良版の安全分類器は、7月20日以降も継続して運用されています。上位版のClaude Mythos 5は、引き続き米国の限定された組織向けにのみ提供されており、一般提供の計画は発表されていません。業務の基幹フローにFable 5を組み込む場合は、Pro・Team Standardではクレジット残高の管理、Max・Team Premiumでは週次上限の消費ペースの両方を確認しておくと安心です。
※ ここから下は、2026年6月9日の発表時にまとめた解説です。Claude Fable 5の性能・特徴・注意点は現在も参考になる情報として残しています。ただし本文中の「6月22日まで無料」などの日程・料金プランの記載は、いずれも過去のスケジュールです。最新の利用条件は上記「【2026年7月20日 更新】」をご覧ください。
Claude Fable 5とは、Anthropic(アンソロピック)が2026年6月9日に発表した、同社が一般提供するモデルとして史上最高性能のAIモデルです。これまで「高性能すぎる」として承認済みパートナーにしか提供されてこなかった「Mythos級」モデルに、悪用を防ぐ安全装置を組み込み、初めて一般公開したものです。
コーディング性能のベンチマークでは他社の最新モデルを大きく引き離し、米決済大手Stripeでは「手作業なら2カ月以上かかる作業を1日で完了した」という実例も報告されています。とはいえ、次々に登場する新モデルの違いまでは追い切れない、という担当者の方も多いはずです。
この記事では、Claude Fable 5の発表内容を整理しながら、何がどう変わって何がすごいのか、料金や利用時の注意点まで順に見ていきます。リリース後3日間の続報(Anthropicの安全装置の方針変更や独立評価の結果)を反映し、2026年6月12日に更新しました。

Claude Fable 5とは?発表の概要
Claude Fable 5は、Anthropicが2026年6月9日に一般提供を開始した最上位のAIモデルです。発表と同日からClaude API・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundry・GitHub Copilotで利用でき、個人向けのClaude.aiアプリやClaude Codeでも有料プランで使えます(出典: Anthropic公式発表、2026年6月9日)。
基本情報まとめ
| 項目 | 内容 |
|---|---|
| 発表日 | 2026年6月9日 |
| 開発元 | Anthropic(米国) |
| モデルID | claude-fable-5 |
| コンテキストウィンドウ | 100万トークン |
| 最大出力 | 128,000トークン |
| API価格 | 入力$10/出力$50(100万トークンあたり) |
| 思考モード | adaptive thinking(常時オン) |
| 提供チャネル | Claude API/Claude.ai/Claude Code/GitHub Copilot/Amazon Bedrock/Vertex AI/Microsoft Foundry |
トークンとは、AIが文章を処理する際の最小単位のことです。コンテキストウィンドウ100万トークンは、長編小説数冊分の文書を一度に読み込ませられる容量に相当します。
「Mythos級」とは?Claude Mythos 5との関係
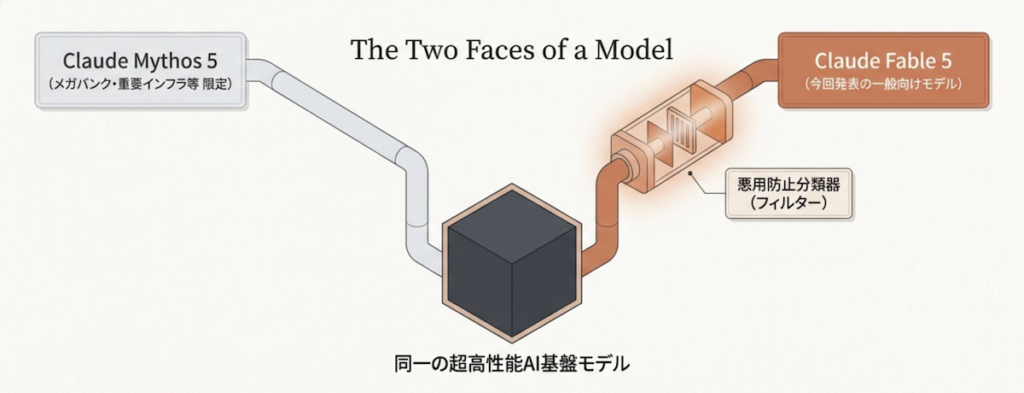
Anthropicは2026年4月から、最高性能モデル「Claude Mythos」をサイバー防御企業や重要インフラ事業者など、承認済みパートナー限定で提供してきました(Project Glasswing)。能力が高すぎるため悪用リスクが大きく、一般公開が見送られていたモデルです(出典: TechCrunch、2026年6月9日)。
Claude Fable 5と、同時発表されたClaude Mythos 5は、同一の基盤モデルです。違いは安全装置の構成だけで、Fable 5には悪用を防ぐ分類器(リクエストの内容を判定する仕組み)が組み込まれ、Mythos 5は安全装置の一部を外した状態で承認済み顧客だけに提供されます。「Fable」の名はラテン語のfabula(語られたもの)に由来し、ギリシャ語のmythosと同系の言葉です。命名自体が「同じモデルの2つの顔」という関係を表しています(出典: Anthropic公式発表)。
何がどう変わった?従来モデル・他社モデルとの違い
変わった点は大きく3つです。性能の天井が上がり、コーディングや分析の主要ベンチマークのほぼすべてで首位に立ちました。「最高性能と安全装置をセットで出す」というリリース方式も今回が初めてです。そして料金は、従来の最上位モデルClaude Opus 4.8の2倍の価格設定になりました。
Claude Opus 4.8からの変更点
これまでの最上位モデルだったClaude Opus 4.8と比べると、次のようになります。
| 項目 | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| API価格(入力/出力、100万トークンあたり) | $10/$50 | $5/$25 |
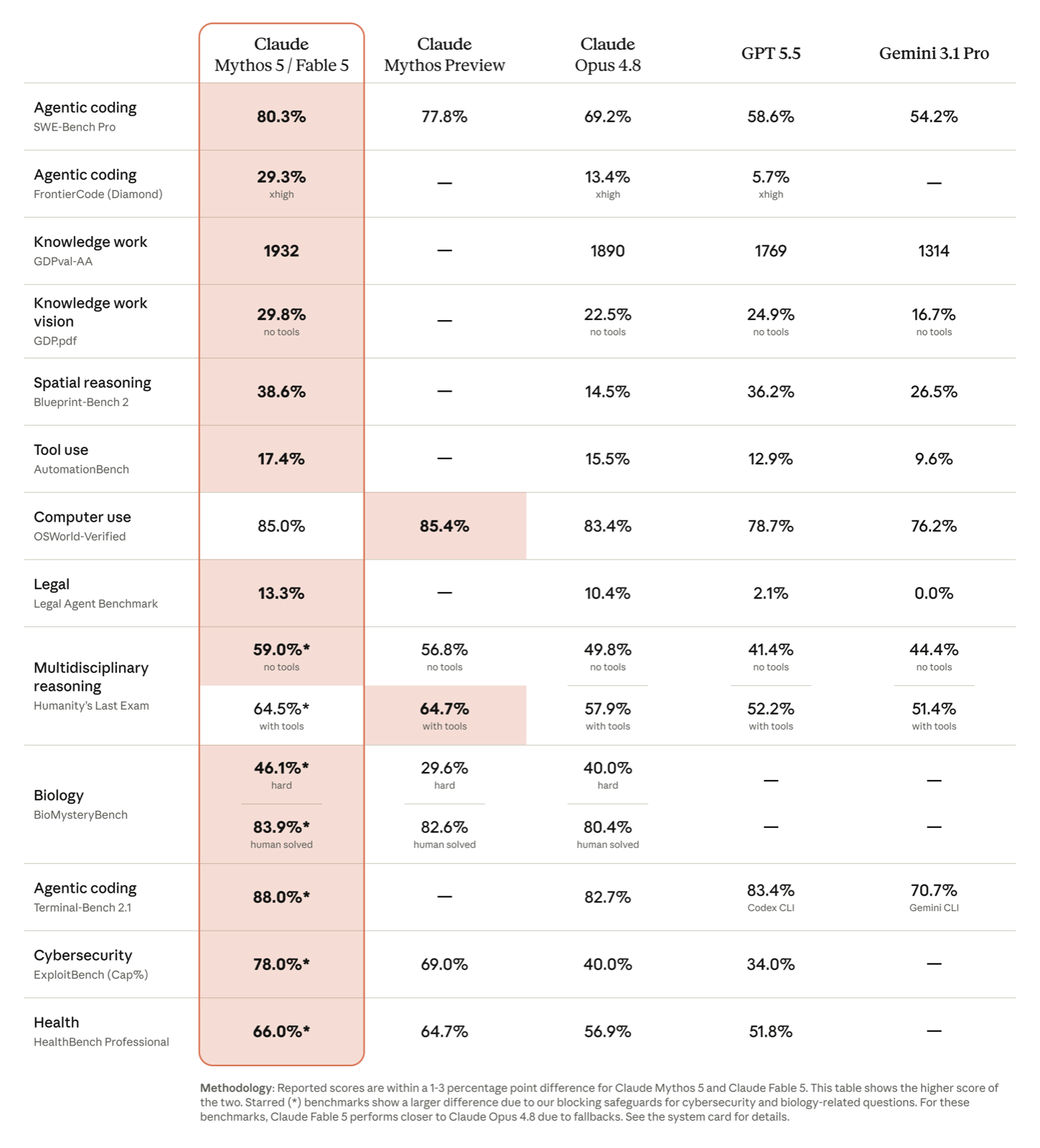
| SWE-bench Pro(実務級コーディング) | 80.3% | 69.2% |
| SWE-bench Verified | 95.0% | 88.6% |
| コンテキストウィンドウ | 100万トークン | 100万トークン |
| 最大出力 | 128,000トークン | 128,000トークン |
| 位置づけ | 最高水準の能力が必要な複雑なタスク向け | 引き続き併売されるOpusティアの最上位 |
(ベンチマーク出典: LLM Stats、2026年6月)
なお、Claude Opus 4.8が廃止されるわけではありません。Anthropicの公式ドキュメントでも、Opus 4.8は引き続き提供され、Fable 5は「最高水準の能力が必要なワークロード向け」の上位枠と位置づけられています(出典: Claude APIドキュメント、2026年6月時点)。
GPT-5.5・Gemini 3.1 Proとの比較
他社の最新モデルとの比較では、コーディングと信頼性の差が目立ちます。
| 項目 | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Pro | 80.3% | 58.6% | 54.2% |
| 知らない質問で誤答する率(AA-Omniscience・低いほど良い) | 36.18% | 85.53% | 49.87% |
| PC操作(OSWorld-Verified) | 85.0% | 78.7% | 76.2% |
| API価格(入力/出力) | $10/$50 | $5/$30 | $2/$12(200Kまで) |
| 弱点 | 価格が最高水準、動画・音声入力に非対応 | 幻覚率の高さ | エージェント型コーディングで劣後 |
(出典: LLM Stats・Tech Jacks Solutionsによる第三者集計、2026年6月)
表中の「知らない質問で誤答する率」は、Artificial AnalysisのAA-Omniscienceベンチマークによる指標です。正答できなかった難問のうち、「分からない」と認めずに誤った答えを出した割合を測るもので、回答全体の誤り率ではありません。数値が高いほど、知らないことでも推測で答えてしまう傾向が強いことを意味します(出典: Artificial Analysis、2026年6月時点)。
価格だけを見ればGemini 3.1 Proが最安ですが、コーディングの実務性能と、知らないことを正直に「分からない」と言える誠実さでは、Claude Fable 5が頭ひとつ抜けています。AI研究者のNathan Lambert氏も、批判的な論点を指摘しつつ「一般に入手可能なモデルの中で間違いなく最も賢い」と評価しています(出典: Interconnects、2026年6月)。GPT-5.5とClaudeを業務シーン別に比べた検証はGPT-5.5とOpus 4.8の比較記事で扱っています。

リリース後の独立評価では見方が割れ始めています。Artificial AnalysisはFable 5を総合知能指数で首位(64.9)と評価した一方、UC Berkeleyの新ベンチマーク「Agents' Last Exam」ではGPT-5.5(24.0%)がFable 5(22.0%)を上回る逆転も起きました(出典: VentureBeat、2026年6月)。単一のベンチマークだけで優劣を判断しない視点が大切です。
Claude Fable 5の何がすごい?注目ポイント7つ
発表内容の中から、特に押さえておきたいポイントを7つに整理します。
①限定提供だった「Mythos級」の頭脳を誰でも使える
最大のニュースは、性能そのものよりも「公開された」ことです。Mythos級モデルはこれまで、日本の3メガバンクや日立製作所などが特別なアクセス権を得て使う、いわば「選ばれた組織専用」のモデルでした。それと同じ基盤モデルが、月額$20のProプラン(約3,000円、1ドル150円換算)でも試せるようになったのです。
②コーディング性能で他社モデルを圧倒
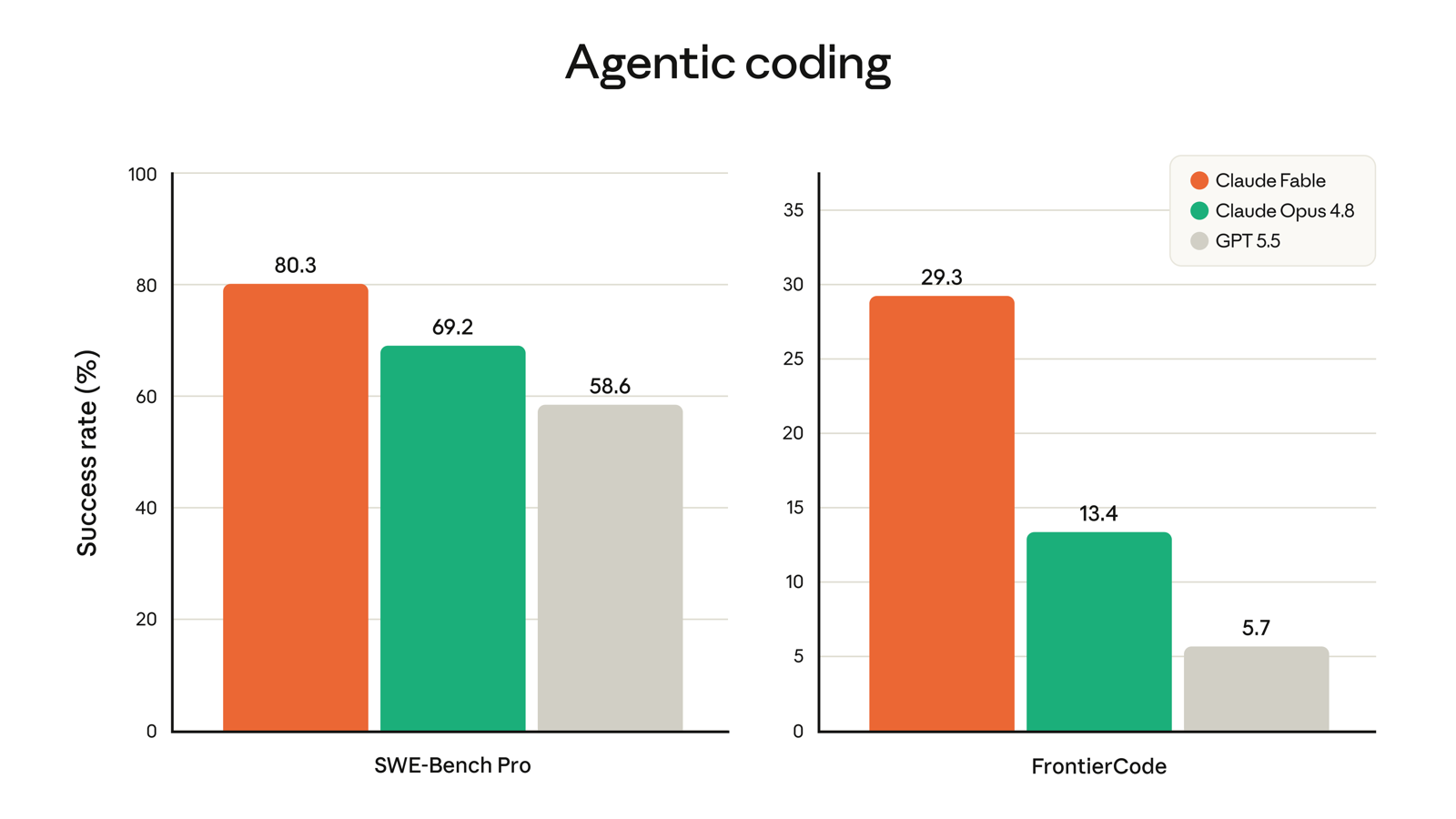
実務級のコーディング能力を測るSWE-bench Proで80.3%を記録し、GPT-5.5(58.6%)やGemini 3.1 Pro(54.2%)を20ポイント以上引き離しました。実プロダクション級の難問を集めたCognitionのFrontierCode評価(Diamond)でも29.3%と、Claude Opus 4.8(13.4%)の2倍以上のスコアです(出典: LLM Stats、2026年6月)。
③「2カ月超の作業を1日で」Stripeの実例
ベンチマークよりわかりやすいのが実例です。決済大手Stripeは、5,000万行に及ぶRubyコードベース全体の移行作業をClaude Fable 5で実施し、フルチームで2カ月超と見積もられていた作業を1日で完了したと報告しています(出典: Anthropic公式発表、2026年6月9日)。レガシーシステムの刷新を抱える企業にとって、試算の前提が変わるレベルの数字です。
④コード以外の知識労働でも最高水準
すごいのはコーディングだけではありません。データ分析企業Hexのコア分析ベンチマークで史上初めて90%を突破し、金融文書分析のHebbia Finance Benchmarkでも最高スコアを記録しました。知識労働全般の能力を測るGDPval-AA(Elo 1932)でも首位です(出典: Anthropic公式発表・LLM Stats、2026年6月)。資料の読み込み・分析・レポート作成といった、多くの企業の日常業務に直結する領域です。
⑤知らないことを「知らない」と言える(幻覚率が最低)
独立評価のAA-Omniscienceでは、正答できなかった問題で「分からない」と認めずに誤答した割合(幻覚率)が36.18%と、GPT-5.5(85.53%)やGemini 3.1 Pro(49.87%)を大きく下回り、主要モデル中で最も低い結果でした(出典: Tech Jacks Solutions・Artificial Analysis、2026年6月)。これは回答全体の誤り率ではなく、知らないことに推測で答えてしまう傾向の強さを測る指標です。ビジネス利用では「賢さ」と同じくらい「知ったかぶりをしないこと」が重要です。契約書や決算資料の分析など、誤りが許されない業務での安心感に直結します。
⑥画面を「見て」操作できる視覚能力
PC操作能力のベンチマークOSWorld-Verifiedで85.0%を記録したほか、画面のピクセル情報だけを頼りにゲーム「ポケットモンスター ファイアレッド」を自律クリアした、スクリーンショットからWebアプリを再構築できる、といったデモも公開されました(出典: Anthropic公式発表、2026年6月9日)。人間と同じように画面を見て操作するAIエージェントの実用化が、一段と現実味を帯びてきました。
⑦「最強と安全の両立」という新しいリリース方式
Claude Fable 5には、サイバー攻撃・生物化学・モデル蒸留(モデルの能力を不正にコピーする手法)に関する危険なリクエストを検知する分類器が組み込まれています。検知された場合は、Claude Opus 4.8が代わりに応答する仕組みです。外部のバグバウンティ(脆弱性発見報奨金プログラム)では1,000時間超のテストでもユニバーサルジェイルブレイク(あらゆる安全装置を突破する手法)は発見されませんでした(出典: Anthropic公式発表、2026年6月9日)。リリース後にはジェイルブレイク成功を主張する研究者も現れましたが、Anthropicは「実害につながる有意な情報増加はない」と反論しており、真偽は検証が続いています(出典: SecurityWeek、2026年6月12日)。「最高性能のモデルを、安全装置とセットで一般公開する」というアプローチ自体が、AI業界の新しい前例になる可能性があります。ただし、この安全設計は公開直後から議論も呼びました。経緯は後述の「リリース後3日間で何が起きた?」で整理しています。
料金と利用方法:いくらで、どこで使える?
API価格とプラン別料金
Claude Fable 5のAPI価格は、入力100万トークンあたり$10、出力100万トークンあたり$50です。Claude Opus 4.8($5/$25)のちょうど2倍ですが、Mythos Preview時代($25/$125)の半額以下に引き下げられています(出典: Claude APIドキュメント、2026年6月時点)。
個人・法人向けプランの料金は次のとおりです(1ドル150円換算の目安額を併記)。
| プラン | 月額料金 | Fable 5の利用 |
|---|---|---|
| Free | $0 | 対象外 |
| Pro | $20(約3,000円) | 6月22日まで追加費用なし |
| Max | $100〜(約15,000円〜) | 6月22日まで追加費用なし |
| Team | 1席$25〜(約3,750円〜) | 6月22日まで追加費用なし |
| Enterprise | 個別見積もり | シート制は6月22日まで追加費用なし |
| API | 従量課金($10/$50) | 発表初日からフル利用可能 |
表中は月払い価格です。年払いの場合はProが月$17相当、Teamが1席月$20相当など割安になります(出典: Claude料金ページ・Anthropic公式発表、2026年6月時点)。
6月22日まで追加費用なしで試せる
Pro・Max・Team・シート制Enterpriseの各プランでは、2026年6月22日までClaude Fable 5を追加費用なしで利用できます。6月23日以降は使用クレジット(利用量に応じた追加課金)の購入が必要になり、提供容量が確保され次第、標準プラン機能として復帰する予定です(出典: Anthropic公式発表、2026年6月9日)。
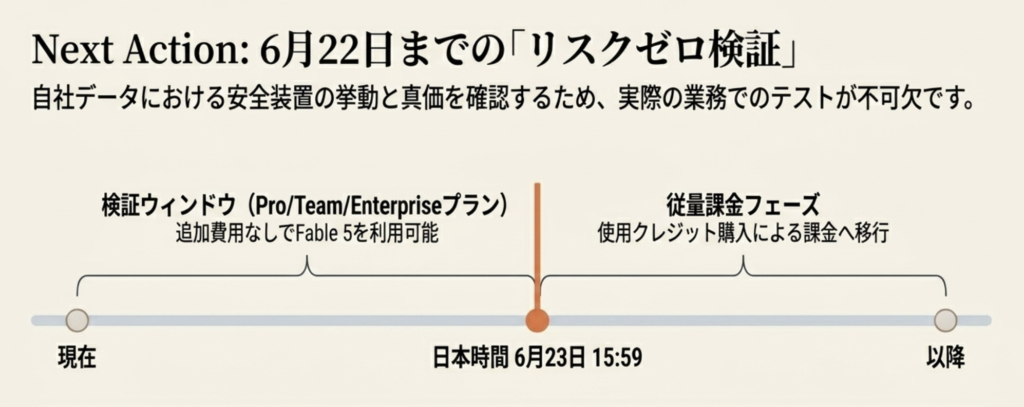
無料期間の終了時刻は米国太平洋時間の6月22日23時59分、日本時間では6月23日15時59分です。APIと使用量ベースのEnterpriseは対象外で、最初から通常課金になります。なおAnthropicは「容量が許せば期間を延長する可能性」にも言及していますが、2026年6月12日時点で延長の告知はありません(出典: Anthropicサポート記事、2026年6月12日時点)。
つまり発表から約2週間は、最上位モデルを通常のプラン料金だけで試せる期間ということです。自社の業務で性能を確かめるなら、この期間が最適です。なお、Claude関連サービスのクレジット制移行の流れはClaude Agent SDKのクレジット制変更の解説でも詳しく整理しています。

利用できるサービス一覧
Claude Fable 5は、次の経路で利用できます。
- Claude.aiアプリ(Web・iOS・Android・デスクトップ)のモデル選択でFable 5を指定する
- Claude Codeで /model コマンドからFable 5を選択する
- GitHub Copilotで利用する(Business/Enterpriseは管理者によるポリシー有効化が必要で、デフォルトはオフ)
- Claude API・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundryから呼び出す
(出典: GitHub公式ブログ・Anthropic公式発表、2026年6月9日)
利用前に知っておきたい注意点
データの取り扱い:30日保持と「学習に使われるか」の整理
企業利用で最も気になるのがデータの取り扱いです。整理すると3層になります。
第1に、個人向けプラン(Free・Pro・Max)では、2025年8月の規約改定以降、チャット内容を学習に使うかどうかを利用者自身が選択する方式になっています。学習を許可する設定になっている場合があるため、プライバシー設定の確認をおすすめします。第2に、Team・Enterprise・APIなどの法人向けサービスは、デフォルトでモデル学習に使用されません(出典: Anthropicプライバシーセンター、2026年6月時点)。
第3に、Fable 5固有のルールとして、全トラフィックに30日間のデータ保持が義務付けられています。これは安全装置の運用のためで、保持されたデータが学習に使われることはありませんが、ゼロデータ保持(ZDR)契約は適用できません。機密性の高いデータを扱う企業は、この点を社内ルールに織り込む必要があります(出典: Claude APIドキュメント・GitHub公式ブログ、2026年6月時点)。AI利用時のセキュリティ対策全般はプロンプトインジェクション対策の記事で解説しています。

高リスクな質問にはOpus 4.8が代わりに答える
前述のとおり、サイバーセキュリティ・生物化学・蒸留に関する高リスクなリクエストは、分類器が検知してClaude Opus 4.8が代わりに応答します。発動はセッションの5%未満で、発動時にはユーザーに通知されます(出典: Anthropic公式発表、2026年6月9日)。
一般的な業務利用で影響を受ける場面は限られますが、セキュリティ調査や創薬研究など該当分野の業務では、想定した性能が出ないケースがあり得ます。なお、Nathan Lambert氏のように「公開ベンチマークのスコアが、フォールバック発生時の実際の体感性能と一致するとは限らない」と指摘する専門家もいます(出典: Interconnects、2026年6月)。6月11日の方針変更により、切り替えはすべて明示的に通知され、APIでは拒否理由が返されるようになりました。防御目的のセキュリティ質問でも分類器が反応したという検証報告があるため、セキュリティ・生物学の業務で使う場合は無料期間中に自社の典型的な質問でテストしておくと安心です(出典: DevelopersIOの検証、2026年6月10日)。
実効コストと使いどころ
見落としやすいのがトークナイザー(文章をトークンに分割する仕組み)の変更です。Fable 5はClaude Opus 4.7で導入された新しいトークナイザーを使っており、同じ文章でも従来モデルより約30%多くトークン化されます。名目上の単価以上に実効コストが上がる要因です(出典: Claude APIドキュメント、2026年6月時点)。定額プランでの利用枠の消費も他モデルより速く、公式サポート情報に「他モデルより高い消費レート」と明記されています。実測では「Opus比で約2倍」「Maxプランの利用枠を1時間未満で使い切った」という報告もあるため、重いエージェントタスクに使う際は残り枠に注意してください(出典: Anthropicサポート記事・利用者の実測報告、2026年6月時点)。
Anthropicの公式ガイドでは、長期間にわたる複雑で多段階のタスクはFable 5、日常業務の標準(迷ったらこれ)はClaude Sonnet 4.6、即時性が求められる軽い処理はClaude Haiku 4.5という使い分けが示されています(出典: Claude公式ガイド、2026年6月時点)。短いタスクではSonnet 4.6との品質差が小さいという検証報告もあり、「全部Fable 5」ではなく、重いタスクに絞って使うのが合理的です。
リリース後3日間で何が起きた?(2026年6月12日時点)
発表から6月12日までの3日間で、Claude Fable 5をめぐる状況はかなり動きました。性能への評価は引き続き高い一方、議論の中心は安全装置とデータの取り扱いという「運用面」に移っています。発表時の情報だけで判断せず、ここまでの経緯を押さえておくと安心です。
「見えない制限」が発覚し、Anthropicが謝罪
リリース直後、技術文書(システムカード)の記載から、AI研究に関するリクエストへの応答品質を通知なく制限する仕組みが組み込まれていたことが分かり、研究者から強い批判を招きました。Anthropicは6月11日に「誤ったトレードオフだった」と謝罪し、該当リクエストはClaude Opus 4.8への切り替えを明示的に通知し、APIでは拒否理由を返す方式に改めています(出典: Fortune・ITmedia、2026年6月10〜12日)。
安全装置の過剰反応も報告されました。「Hello」というあいさつや、がん(cancer)という単語を含む生物学の質問まで誤ってブロックされた事例があり、Anthropicは誤検知の削減を進めるとしています(出典: The Register、2026年6月10日)。Artificial Analysisの実測ではフォールバック発生率が約8%と、公称の「5%未満」を上回ったという報告もあります。
独立評価と実測レビューは賛否両論
第三者評価は一枚岩ではありません。総合知能指数の首位評価がある一方で、Endor Labsの脆弱性修正ベンチマーク(実在の脆弱性200件)では5位の中位にとどまり、ベンチマークの解き方に「訓練データの暗記」とみられる挙動が38件確認されたという指摘も出ています(出典: Endor Labs、2026年6月11日)。
日本の実測レビューでも評価は分かれています。「バグ検出が的確で開発がはかどる」という高評価がある一方、「OpusやGPT-5.5との差をあまり感じない。通常の開発には過剰」という冷静な見方もあります(出典: note実測レビュー各記事、2026年6月10〜12日)。応答速度は、思考の深さを最大にした場合に最初の応答まで100秒超という計測もあり、軽いタスクには向きません。前述の「重いタスクに絞って使う」という使い分けが、実測でも裏付けられた形です。
企業利用への影響:Microsoftが社内利用を一時制限
企業利用の観点で大きいのは、Microsoftが30日データ保持ポリシーを理由に、従業員によるFable 5利用を一時制限したことです。恒久的な禁止ではなく、法務チームの審査中の予防措置とされていますが、ゼロデータ保持が必要な企業では当面利用が難しい状況です(出典: The Verge報道のGIGAZINE記事、2026年6月11日)。Amazon Bedrock経由の場合は、2026年6月12日時点で東京リージョン未対応(米国東部・ストックホルムのみ)という制約の報告もあるため、国内インフラ要件がある場合は事前確認が必要です。
日本での反響と企業の動き
日本では発表翌日の2026年6月10日朝から、ITmedia・Impress Watch・PC Watch・窓の杜・日本経済新聞・日経クロステック・ギズモード・ジャパンが一斉に報道しました。ITmediaや日経は「ミュトス級」というカタカナ表記を使い、ギズモード・ジャパンはベンチマーク結果を「独走といっていい状態」と評しています(出典: ITmedia NEWS・ギズモード・ジャパン、2026年6月10日)。
日本企業の動きも活発です。日立製作所は2026年6月5日にProject Glasswing参画を発表し、トレンドマイクロも6月4日に参加を公表しました。富士通は5月27日にAnthropicとの提携を発表しており、3メガバンクもMythosへのアクセスに向けた官民連携が報じられています(出典: トレンドマイクロ公式プレスリリース・Ledge.ai、2026年5〜6月)。Fable 5の一般公開は、こうした限定提供の流れが一般企業にまで開放された転換点です。
報道はその後も続いています。6月10日には東京で開発者イベント「Code with Claude Tokyo」が開催され、ASCII・Ledge.ai・CNET Japanの解説記事や窓の杜の実用レビューなど後追い報道が出そろいました(出典: CodeZine、2026年6月10日)。国内SaaSでは、LINE運用支援のサブスクラインがAIエージェント機能へのFable 5搭載を発表するなど、採用の動きも始まっています(出典: PR TIMES、2026年6月11日)。
まとめ:Claude Fable 5発表をどう受け止めるか
Claude Fable 5は、「選ばれた組織しか使えなかった最高性能AIが、安全装置つきで誰でも使えるようになった」という点で、単なる性能アップデートを超えた発表です。コーディングでは他社を大きく引き離し、分析・金融文書・PC操作でも最高水準のスコアを記録しました。知らないことを知らないと言える誠実さ(幻覚率の低さ)は、ビジネス利用での信頼性に直結します。
正直なところ、すべての業務に必要なモデルではありません。価格はOpus 4.8の2倍で、トークナイザーの変更により実効コストはさらに上がります。30日データ保持などの固有ルールもあるため、「どの業務に使い、どの業務はSonnet 4.6で済ませるか」の見極めが導入の成否を分けます。
リリース後の3日間は、性能は高く評価されつつも、見えない制限への批判とAnthropicの謝罪、Microsoftの社内利用一時制限など、運用面の議論が続きました。性能の評価とあわせて、データの取り扱いを含めた社内ルールの整備をセットで考える必要があります。
幸い、2026年6月22日まではPro以上のプランで追加費用なしに試せます。まずはこの期間中に、自社で最も時間のかかっている業務を1つ選んで、Fable 5に任せてみるところから始めてみてください。
【2026年7月20日更新】上記の無料期間は、7月1日の再開後も7月12日→7月19日と2度延長された末、2026年7月20日に最終方針へ切り替わりました。Max・Team Premiumプランは週次利用上限の最大50%まで恒久的に追加費用なしとなった一方、Pro・Team Standardプランは使用クレジット制に移行しています。Pro以下のプランで導入を検討している場合は、一回限りの無料クレジットの範囲でまず自社業務との相性を確かめるのがおすすめです。
Claude Fable 5に関するよくある質問(FAQ)
Q1. Claude Fable 5は無料で使えますか?
【2026年7月20日更新】Freeプランは対象外です。Max・Team Premiumプランでは恒久的に、週次利用上限の最大50%の範囲で追加費用なしで利用できます(期限なし)。一方Pro・Team Standardプランは使用クレジット(入力$10/出力$50)による従量課金制で、移行にあたり一回限りの無料クレジットが付与されます(出典: Anthropic公式ヘルプセンター、2026年7月18日更新)。
Q2. Claude Fable 5とClaude Mythos 5の違いは何ですか?
両者は同一の基盤モデルで、違いは安全装置の有無です。Fable 5は悪用を防ぐ分類器を組み込んだ一般公開版、Mythos 5は安全装置の一部を外した版で、Project Glasswingの承認顧客(サイバー防御企業・研究機関等)だけが利用できます。
Q3. Claude Opus 4.8はなくなりますか?
なくなりません。Opus 4.8(API価格$5/$25)は引き続き提供され、Fable 5は最高水準の能力が必要なタスク向けの上位選択肢という位置づけです(出典: Claude APIドキュメント、2026年6月時点)。
Q4. 入力したデータはAIの学習に使われますか?
Team・Enterprise・APIなどの法人向けサービスでは、デフォルトで学習に使用されません。個人向けプラン(Free・Pro・Max)は学習利用の許否を利用者が選択する方式のため、プライバシー設定を確認してください。なおFable 5は安全運用のため全トラフィックを30日間保持しますが、このデータも学習には使われません。
Q5. Claude Fable 5はどんな作業に向いていますか?
大規模なコード移行、多段階のエージェント業務、複雑な文書分析・調査など、長く複雑なタスクに向いています。メール作成や要約などの日常業務はSonnet 4.6が標準とされており、使い分けがコスト効率の鍵になります(出典: Claude公式ガイド、2026年6月時点)。
Q6. どうやって使い始めればよいですか?
Claude.aiの有料プランに加入し、モデル選択でFable 5を指定するのが最も手軽です。開発者はClaude APIまたはClaude Codeの /model コマンドから、GitHub Copilot利用企業は管理者がポリシーを有効化することで利用できます。
Q7. Claude Fable 5が一時使えなくなっていたのはなぜですか?
2026年6月12日に米国政府が国家安全保障を根拠とする輸出管理指令を出し、Anthropicが全世界でアクセスを停止していたためです。発端は、Amazonの研究者が報告した「安全装置を回避してソフトウェアの脆弱性を特定させる」ジェイルブレイク手法でした。Anthropicが改良版の安全分類器(該当手法を99%以上ブロック)などの対策を講じた結果、6月30日に指令は解除され、7月1日から利用が再開されています(出典: Anthropic公式発表、2026年6月30日)。
Q8. Proプランでは今後Fable 5を使えなくなりますか?
完全に使えなくなるわけではありませんが、2026年7月20日以降はプランの利用上限に含まれず、使用クレジット(入力$10/出力$50、100万トークンあたり)を購入する必要があります。移行にあたり一回限りの無料クレジット(報道では$100相当)が付与されるため、まずはその範囲で評価し、継続利用する場合はコストを踏まえて利用場面を絞り込むのが現実的です。恒久的に追加費用なしで使えるのはMax・Team Premiumプランのみです(出典: Anthropic公式ヘルプセンター、2026年7月18日更新)。



