
アイデア優先度フレームワークとは、複数の施策・機能・新規事業案を共通の評価軸でスコアリングし、実行順序を客観的に決めるための手法です。代表格であるRICEスコアリングはIntercomの元プロダクトマネージャーSean McBrideが考案し、ICEスコアリングはSean Ellis("growth hacking"の提唱者・共著書『Hacking Growth』)が広めました。本記事では、新規事業・新規プロダクト開発の現場で30件以上のアイデアを抱える経営者・PdM向けに、主要7フレームワークの全体像、RICE/ICEの計算式と使い分け、スプレッドシートで運用する実践ステップまでを一気通貫で解説します。なお、アイデアそのものの発想法はアイデアの出し方フレームワーク総論で別途解説しているので、そちらも合わせて参照してください。
目次
アイデア優先度フレームワークとは|なぜ直感では失敗するのか
アイデア優先度フレームワークとは、複数の候補案を共通の評価軸で点数化し、実行順を機械的に決定する仕組みのことです。直感や声の大きさで決める従来型の意思決定を排除し、チーム内の合意形成を加速させる目的で使われます。
直感で決めると起こる3つの失敗パターン
スタートアップ初期では、創業者の確信や声の大きいメンバーの意見で施策が決まりがちです。代表的な失敗は次の3つに集約されます。
- HiPPO問題:HiPPO(Highest Paid Person's Opinion/最も給与の高い人の意見)に意思決定が引きずられ、データが軽視される
- キラキラ症候群:直近で目にしたトレンドや競合の動きに反応し、優先度が毎週入れ替わる
- コンフィデンス過信:未検証の仮説を「自分は確信している」と評価し、ハズレ施策に資源を投下する
これらは事業の大小を問わず発生しますが、リソースが限られるスタートアップほどダメージが大きくなります。
スコアリング型と分類型の違い
優先度フレームワークは大きく2タイプに分かれます。スコアリング型は数値計算で順位をつける手法、分類型は要件をカテゴリに振り分ける手法です。
比較表①:スコアリング型と分類型の違い
| 比較軸 | スコアリング型 | 分類型 |
|---|---|---|
| 代表例 | RICE / ICE / Cost of Delay | MoSCoW / Kano / Value vs Effort |
| 出力 | 数値(順位付け可能) | カテゴリ(必須/重要/任意など) |
| 向く用途 | 大量アイデアの相対比較 | リリース範囲の決定・要件整理 |
| 必要データ量 | 多い | 少ない |
| 客観性 | 比較的高い | 主観性が残る |
| 議論時間 | やや長い | 短い |
両者は二者択一ではなく、ディスカバリー段階で分類型、開発バックログ段階でスコアリング型といった併用が実務では主流です。
優先度評価フレームワーク7選|一覧で押さえる主要手法
新規事業・プロダクト開発の現場で実際に使われている代表的な7つのフレームワークを、性質ごとに整理します。各手法は得意領域が異なるため、自社のフェーズと意思決定の粒度に応じて選びます。
① RICEスコアリング(定量・データドリブン型)
Reach × Impact × Confidence ÷ Effort で算出する4要素モデル。Intercomで考案され、Reach(到達ユーザー数)を独立変数として扱う点が最大の特徴です。データドリブンな意思決定を求められるシリーズA以降のスタートアップに適します。
② ICEスコアリング(定量・スピード型)
Impact × Confidence × Ease の3要素を1〜10で採点する簡易モデル。Sean EllisがDropboxやLogMeInのグロース実験で運用したことで知られます。1アイデアあたり1分以内で評価できる速度がスタートアップ初期に向きます。
③ MoSCoW法(分類型)
要件を Must have / Should have / Could have / Won't have の4カテゴリに分類する手法。1994年にDai Clegg(当時Oracle)が考案し、DSDM(Dynamic Systems Development Method)の中で広まりました。MVPのリリース範囲を切る場面で強力に機能します。
④ Kanoモデル(顧客満足度型)
東京理科大学の狩野紀昭教授が1980年代に提唱したフレームワーク。機能を Basic(当たり前品質)/Performance(一元的品質)/Delighter(魅力品質) に分類し、顧客満足度の観点から優先度を判断します。プロダクトディスカバリー初期に有効です。
⑤ Value vs Effort マトリクス(2軸型)
価値(縦軸)×工数(横軸)の2×2マトリクスに案件を配置し、「Quick Wins(高価値・低工数)」「Big Bets(高価値・高工数)」「Fill-ins(低価値・低工数)」「Time Sinks(低価値・高工数)」の4象限で判断する方法です。日本ではペイオフマトリクスとしても広く使われており、RICEの簡易版とも言える構造のため、議論のたたき台として軽量に運用できます。

⑥ Cost of Delay(経済合理性型)
Donald Reinertsenが著書『The Principles of Product Development Flow』で体系化した手法。「この施策を実行しないことによる週次の機会損失額」を金額換算し、CD3(Cost of Delay Divided by Duration)で順位付けします。SAFe(Scaled Agile Framework)採用企業で広く使われます。
⑦ Opportunity Scoring(機会発見型)
Anthony UlwickがOutcome-Driven Innovationで提唱した手法。顧客に「重要度」と「満足度」を10点満点で問い、Opportunity Score = 重要度 + max(重要度 − 満足度, 0) で機会を可視化します。「重要だが満足していない」領域、つまり事業機会が数値で見えてきます。
比較表②:7フレームワークの一覧
| # | 手法 | タイプ | 評価軸 | 向くフェーズ | 主な弱み |
|---|---|---|---|---|---|
| 1 | RICE | 定量 | Reach×Impact×Confidence÷Effort | PMF後・スケール期 | データ収集の負荷が高い |
| 2 | ICE | 定量 | Impact×Confidence×Ease(各1〜10) | プレシード〜PMF前 | 主観性・Reach未反映 |
| 3 | MoSCoW | 分類 | 必須/重要/任意/対象外 | MVPリリース直前 | 順位付けはできない |
| 4 | Kano | 分類 | 当たり前/一元的/魅力品質 | ディスカバリー初期 | 顧客調査が前提 |
| 5 | Value vs Effort | 定量 | 価値×工数 | 全フェーズ・議論用 | 粒度が粗い |
| 6 | Cost of Delay | 定量 | 機会損失額/期間 | エンタープライズ開発 | 金額換算の難易度 |
| 7 | Opportunity Scoring | 定量 | 重要度+未充足度 | 顧客課題発見 | 顧客調査が必要 |
本記事の主役であるRICEとICEは、スコアリング型の中でも実装コストと客観性のバランスが優れるため、新規事業・PdM領域で最も普及しています。
RICEスコアリングの計算式と使い方|4要素を分解する
RICEスコアは Reach × Impact × Confidence ÷ Effort で計算します。Sean McBrideがIntercomのGrowthチームで運用するために設計した手法で、「気持ちの強さ」を数値に変換することを目的としています。
各要素のスコア基準と具体例
Reach(リーチ)
施策が一定期間内に何人のユーザーに影響するかを実数で記入します。Intercom公式ガイドでは「四半期あたりの顧客数」「月次のトランザクション数」など、既存のKPIで計測可能な単位を使うことが推奨されています。
- 例:オンボーディング改善 → 「月間新規ユーザー2,000人」 = Reach 2,000
Impact(インパクト)
ユーザー1人あたりに与える効果の強さを離散値で表現します。Intercom原典では次の5段階が用いられます。
- 3:Massive impact(劇的)
- 2:High(大きい)
- 1:Medium(中)
- 0.5:Low(小さい)
- 0.25:Minimal(ごくわずか)
連続値ではなく離散値を使うのは、「2.7」など過度に細かい議論を防ぐためです。
Confidence(コンフィデンス)
Impact・Reach・Effortの見積もりにどれだけ自信があるかをパーセンテージで表します。
- 100%:High confidence(堅いデータあり)
- 80%:Medium confidence(一定の根拠あり)
- 50%:Low confidence(仮説段階・ムーンショット)
ProductPlanのガイドでは50%未満の案件は「Confidenceの暴落ゾーン」として、原則実行候補から除外することが推奨されています。
Effort(エフォート)
実装に必要な工数をperson-month(人月)で見積もります。「エンジニア2名が2ヶ月でリリース」なら4 person-months。設計・QA・PM工数も含めて見積もります。
RICEスコアの記入例
架空のSaaSスタートアップで3案を比較すると次のとおりです。
| 案件 | Reach(人/月) | Impact | Confidence | Effort(人月) | RICEスコア |
|---|---|---|---|---|---|
| A. オンボーディング動画追加 | 2,000 | 1 | 80% | 1 | 1,600 |
| B. 通知機能リファクタ | 5,000 | 0.5 | 100% | 3 | 833 |
| C. AI搭載レコメンド機能 | 1,500 | 3 | 50% | 6 | 375 |
C案は「劇的なインパクト」を見込みつつもConfidenceが50%・Effort 6人月のため、スコア上はA案が最優先となります。直感だけだとC案を選びがちな状況で、RICEは数値で再考を促します。
ICEスコアリングの計算式と使い方|3要素でスピード評価する
ICEスコアは Impact × Confidence × Ease で計算する3要素モデルです。Sean EllisがDropboxやLogMeIn等のグロースチームで実験を高速回転させるために運用したフレームワークとして広まりました。
各要素のスコア基準(1〜10)
ICEは全要素を1〜10の整数で採点します。各要素の基準は次のとおりです。
- Impact:その実験が主要KPI(MAU、CVR、LTVなど)にどれだけ影響するか
- Confidence:その効果が出ると確信できる度合い(過去の類似実験データ・顧客インタビュー量で判断)
- Ease:実装の容易さ(Effortの逆方向。簡単なほど高得点)
各要素を10点満点で採点するため、最大スコアは1,000、最小は1になります。
ICE記入例
| 実験案 | Impact | Confidence | Ease | ICEスコア |
|---|---|---|---|---|
| A. メールサブジェクトのABテスト | 5 | 8 | 9 | 360 |
| B. 価格表ページのコピー変更 | 7 | 7 | 8 | 392 |
| C. 新しい紹介プログラムの設計 | 9 | 5 | 3 | 135 |
A案・B案は2〜3日で実行できる軽量実験。C案は影響度こそ高いものの実装が重く、Easeで大きく沈みます。ICEは「実験を回す速度」を最大化したいときに強みを発揮します。
ICEとRICEの構造的な違い
両者の本質的な違いはReachを独立変数として扱うかどうかです。
| 比較軸 | RICE | ICE |
|---|---|---|
| 要素数 | 4 | 3 |
| Reachの扱い | 独立変数(人数) | Impactに内包 |
| Effortの扱い | 人月(連続値) | Ease 1〜10(逆方向) |
| 採点時間 | 5〜15分/案 | 30秒〜1分/案 |
| 必要データ | 利用ログ・顧客数 | 仮説と直感の整理 |
| 適合フェーズ | PMF後・スケール期 | プレシード〜PMF探索期 |
The original growth hackerとしてSean Ellisがインタビュー(Lenny's Newsletter)で語っているように、ICEは「データが足りないが、いますぐ次の実験を決める必要がある」状況を想定して設計されています。一方のRICEは、Reachというデータ前提があるからこそ機能する仕組みです。
RICEとICEはどちらを使う?フェーズ別の選び方
「RICEが上位互換」と言われがちですが、実務での選び方は事業フェーズと使えるデータの量で決まります。
スタートアップ初期はICEが向く理由
プレシード〜シードのスタートアップでは、Reachに当てはめるべき実数(MAU、月次トランザクション数)がそもそも存在しません。仮にRICEを使ってもReach=数十人の数字に振り回され、実態と乖離した順位が出ます。
- データが少ない時期は仮説検証の速度が事業の生存率を決める
- ICEは1案件1分以内で評価でき、毎週のアイデア整理に組み込める
- 創業者・PdM・エンジニアが同席する1時間ミーティングで20〜30案を捌ける
PMF後・スケール期はRICEが向く理由
シリーズA以降は社内に利用ログが蓄積し、Reachを実数で扱えるようになります。投資家や経営会議で意思決定の根拠を求められる場面も増え、RICEの数値説明力が活きます。
- Reachを反映することでニッチ機能の過剰評価を防げる
- person-monthベースのEffortは経営計画と接続しやすい
- 30〜100案件を扱うロードマップ会議に耐える
状況別おすすめマトリクス
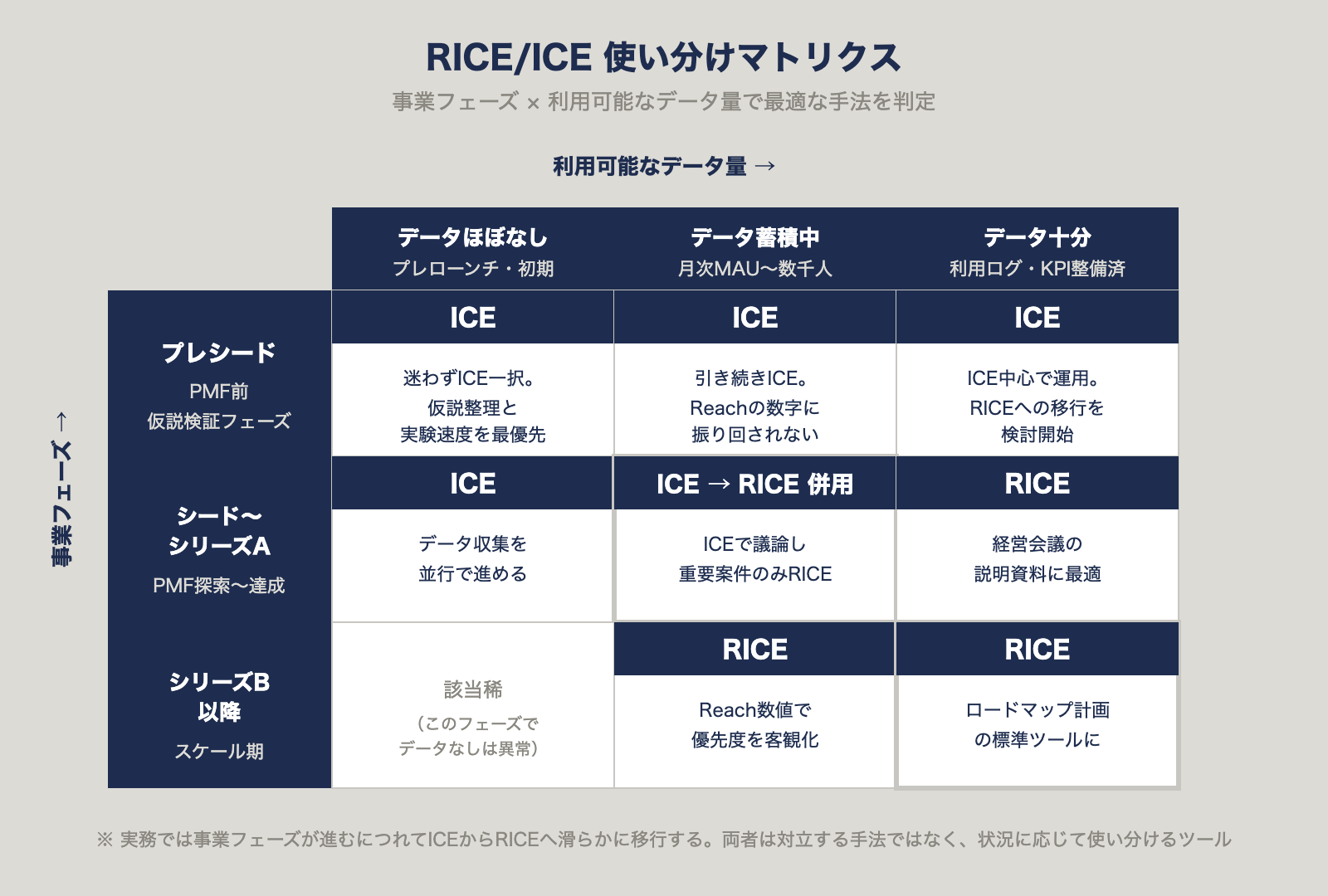
比較表③:事業フェーズ × データ有無
| 事業フェーズ \ データ量 | データほぼなし | データ蓄積中 | データ十分 |
|---|---|---|---|
| プレシード(〜PMF前) | ICE | ICE | ICE |
| シード〜シリーズA | ICE | ICE → RICE併用 | RICE |
| シリーズB以降 | (該当稀) | RICE | RICE |
「ICEで実験を回しながらデータを貯め、ある時点でRICEに切り替える」という移行パスが最も自然です。両者は対立する手法ではなく、事業フェーズに沿って入れ替えていくツールと捉えるべきです。
RICE/ICEを実務で運用する5ステップ|スプレッドシート実装例
創業1〜2年・5〜10名のチームがGoogle スプレッドシートでRICE/ICEを運用する場合の手順を、5ステップに分けて整理します。
ステップ1:評価対象アイデアを棚卸しする
ProductBoard・Notion・Linear・Jiraのいずれかでバラついているアイデアを1つのシートに集約します。1行=1アイデアとし、最低限「タイトル」「要約3行」「想起した日付」「起案者」を埋めます。
棚卸し段階ではスコアをつけないことが鉄則です。先にスコアを意識すると、表現を盛ったり工数を過小申告するバイアスが入ります。
ステップ2:スコア基準を全員で合意する
採点基準のすり合わせを30分行います。RICEなら「Impact 3はどんなレベルか」、ICEなら「Confidence 8と5の境目はどこか」を、過去案件を例にチームで合意します。
合意した基準はシートの別タブに「採点ガイド」として明文化します。これがないと、毎週の採点で議論が再燃します。
ステップ3:複数人で独立採点する
3〜5名が個別に・他人のスコアを見ずに採点します。GoogleフォームやスプレッドシートのProtected Rangeで他人のスコアが見えない状態を作ります。
複数採点は採点者バイアスを統計的に薄める効果があります。3名なら平均値、5名なら中央値の使用が無難です。
ステップ4:差分の大きい項目を議論する
採点者間でスコアが3点以上ズレた項目だけを抽出し、5〜10分ずつ議論します。全項目を議論するとミーティングが破綻するため、ばらつき項目に絞ることが肝要です。
議論の結果、採点を変更するか「合意できない」を許容するかをチームで決め、シートに記録します。
ステップ5:スコア順に並べ、上位を実行に回す
確定したスコアで降順ソートし、上位20%を直近スプリント、上位50%を次四半期候補、それ以下は保留として運用します。スプリントレトロスペクティブ時にスコアを再採点し、現実とのズレを補正します。
スプレッドシート列構成のサンプル
| 列名 | 内容 | 入力例 |
|---|---|---|
| ID | 連番 | A-001 |
| タイトル | 施策名(1行) | オンボーディング動画追加 |
| 要約 | 3行以内 | 初回ログイン後の離脱を減らす目的の60秒動画 |
| 起案日 | YYYY-MM-DD | 2026-04-15 |
| 起案者 | 名前 | 佐藤 |
| Reach | 月次到達ユーザー数 | 2,000 |
| Impact | 0.25/0.5/1/2/3 | 1 |
| Confidence | 50/80/100% | 80% |
| Effort | 人月 | 1 |
| RICEスコア | 自動計算 | 1,600 |
| 順位 | 自動計算 | 3 |
| ステータス | 候補/実行中/完了/保留 | 候補 |
数式は =Reach*Impact*Confidence/Effort を入れるだけで運用できます。
よくある失敗と対処法|スコアリングが形骸化しない3つのコツ
RICE/ICEを導入しても、半年後に形骸化して使われなくなる事例が後を絶ちません。代表的な3失敗とその回避策を整理します。
失敗①:1人だけで採点して「数字の独裁」になる
PdMやCEOが1人で採点した数値に対し、他メンバーが「客観的だから」と無批判に従う状態。スコアの見た目で意思決定が硬直化し、議論が消えます。
対処法:必ず3名以上で独立採点し、ばらつきを起点に議論する仕組みを組み込む。スコアは「議論の出発点」であり「結論」ではないと明文化する。
失敗②:Confidenceを甘く見積もる
特にCEO・創業者は自分の発案にConfidence 90%以上をつけがちです。これがRICE/ICEの結果を歪め、ハズレ施策に資源が流れます。
対処法:Confidenceは「外部データ/顧客インタビュー数/類似実験の成功率」など根拠の質で機械的に決める。
- データなし=50%上限
- 顧客5名以上の証言あり=80%上限
- 同種施策の過去実績あり=100%可
失敗③:上位だけを実行し、定性的に重要な案件を捨てる
スコア上位ばかり実行すると、長期的な技術負債解消や倫理・ブランド観点の施策が後回しになります。半年後に技術負債で開発速度が半減する、というパターンです。
対処法:四半期スプリントの20%を「スコア外枠」として確保し、技術負債・コンプライアンス・ブランド整合の案件に充てる。GoogleやSpotifyが「20%ルール」と呼んできた発想に近い運用です。
まとめ|RICE/ICEは「議論の共通言語」として機能させる
RICE/ICEの真価は、スコアの絶対値が正しいことではなく、チーム全員が同じ評価軸でアイデアを語れるようになることにあります。Sean McBrideもSean Ellisも、各々の原典で「数字は議論の入口であり、機械的な実行命令ではない」と明言しています。技術の成熟度から投資タイミングを判断する観点では、ガートナー・ハイプサイクルの使い方もあわせて参考になります。

新規事業・新規プロダクト開発の現場では、まずICEで毎週の実験を高速に回し、PMFが見えてきた段階でRICEに移行する運用が再現性の高いパターンです。MoSCoWやKano、Value vs Effortは局面に応じて補助的に使い、Cost of Delay・Opportunity Scoringは事業がスケールしてからの選択肢として温存します。
評価フレームワークは「導入したら終わり」のツールではなく、チームの言語を整備するOSです。最初の1ヶ月は採点基準の合意に時間を割き、3ヶ月で運用の癖をつけ、6ヶ月で形骸化を防ぐ仕組みに育てる。この時間軸で取り組むことを推奨します。なお、採点基準の合意以前に新規事業の全体像をチームで握りたい場合は、インセプションデックの10項目から始めると、優先度議論の土台が整いやすくなります。
よくある質問
Q1. RICEのImpactスコア(0.25/0.5/1/2/3)はどう決めればいいですか?
主要KPIへの寄与度を5段階の離散値で決めます。Intercomの原典では「過去に大成功した自社施策=Impact 3」「失敗した施策=0.25」を基準にチームで標準化することが推奨されています。連続値ではなく離散値を使う理由は、「2.7か2.8か」のような微差議論を排除するためです。
Q2. ICEスコアリングの主観性をどう抑えればいいですか?
3〜5名による独立採点と、採点ガイドラインの明文化が二大対策です。Confidenceは「データの裏付けがある=7点以上」「仮説段階=5点以下」のように根拠ベースで機械的に決定すると、人によるばらつきを大きく減らせます。
Q3. RICE/ICEと、MoSCoWやKanoは併用できますか?
併用が現実的です。プロダクトディスカバリー初期にKanoで機能カテゴリを整理し、開発バックログ段階でRICE/ICEで順位付け、リリース範囲を切る直前にMoSCoWで必須要件を確定する流れが定番です。1つのフレームワークで全てを解こうとせず、局面ごとにツールを切り替えます。
Q4. Effortの見積もりが大きくブレる場合の対処法は?
3点見積もり(楽観・標準・悲観の3値)を採用し、標準値をRICEに入力します。同時に、見積もり誤差が大きい案件はConfidenceを下げることで、Effortのブレが結果に過剰に反映されないよう調整します。エンジニア・PM・デザイナーが個別に見積もり、最大値を採用するのも有効です。
Q5. スタートアップ創業期、データがほぼない段階で使うならどちら?
ICE一択です。Reachに入れる実数がない状態でRICEを使っても、数字遊びになります。ICEで毎週20〜30案を採点し、実験を高速に回しながらデータを貯め、月間アクティブユーザー1,000人を超えたあたりからRICE併用に切り替える運用が現実的です。
Q6. チームで採点が割れたときはどう合意形成すべきですか?
「3点以上ズレた項目に限って5〜10分議論する」ルールが効率的です。全項目を議論するとミーティングが破綻します。議論しても合意できない場合は、無理に合わせずスコア幅(例:Impact 1〜2)として記録し、Confidenceを下げることで対応します。スコアより「議論の透明性」を優先する姿勢が、長期運用のカギになります。



